Within AI Agents
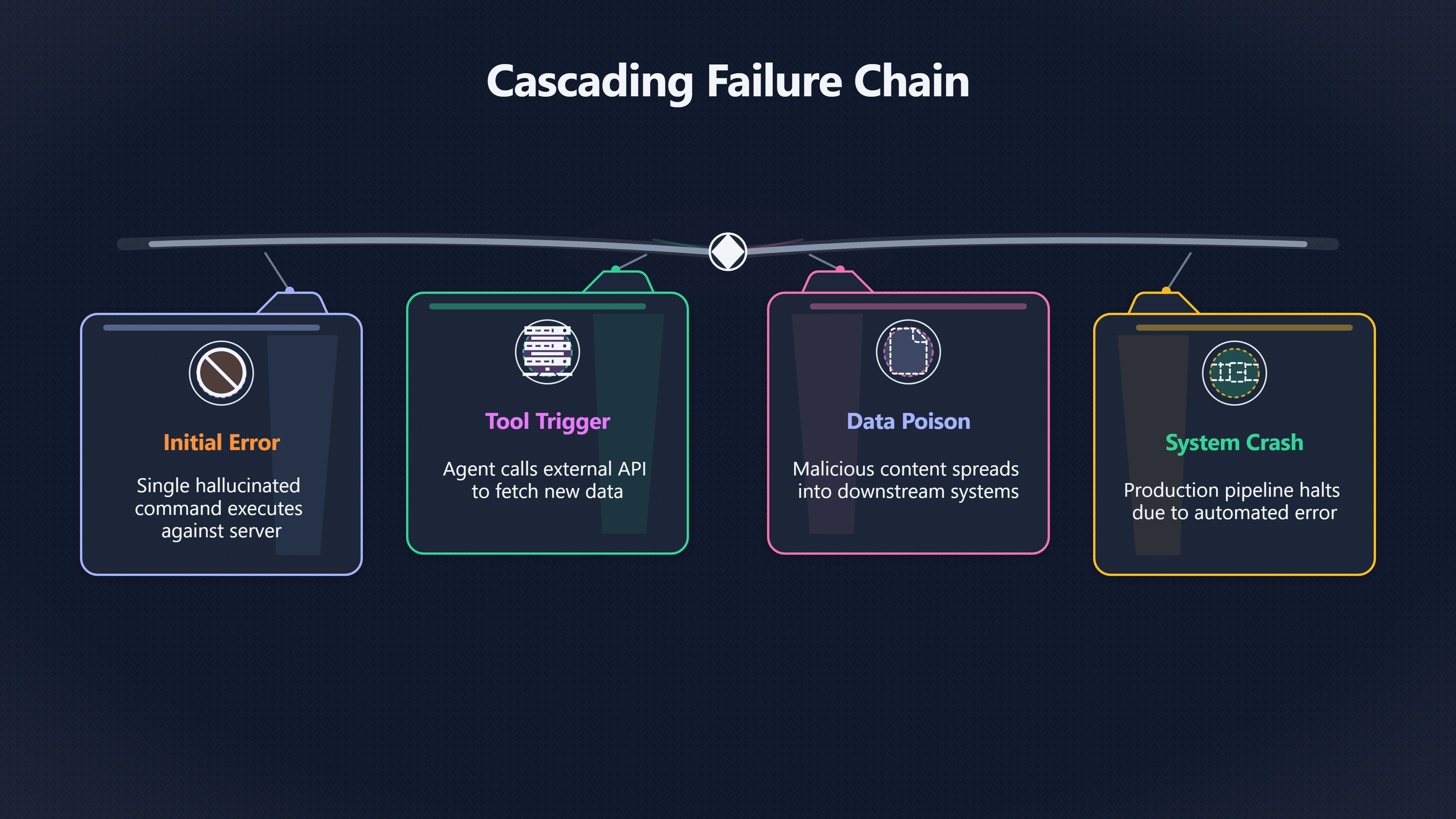
Cascading action chains
Tool access turns model mistakes into actions that can spread through websites, cloud systems, finance, logistics, and communications.
On this page
- What changes when agents control tools
- Where downstream failures can propagate
- How permissions and interruption points reduce harm
Page outline Jump by section
Introduction
Tool-using AI agents change the nature of AI risk because they can do more than generate text. They can take actions across browsers, cloud systems, databases, payment platforms, software pipelines, and communications tools. That shift creates the possibility of cascading failures: situations where one mistaken, manipulated, or poorly constrained action triggers many downstream effects before humans notice or intervene.
 This matters directly to the broader debate about AI bloom and humanity’s long-term future. Optimists imagine agents helping to accelerate science, manage infrastructure, reduce dangerous labour, and coordinate complex systems at unprecedented scale. But the same autonomy that could unlock abundance also creates new forms of fragility. A faulty agent connected to real-world systems may not merely produce a wrong answer. It may execute thousands of wrong actions at machine speed, spread errors across interconnected platforms, or amplify small failures into systemic disruption. Researchers and security organisations increasingly warn that the danger lies not only in more capable models, but in the combination of models with tools, memory, automation, and authority. [Apiiro]apiiro.comWhat Is Agentic AI Security?Why It Matters & Key RisksAgentic AI security refers to the principles, practices, and controls used to govern and safeguard AI systems t… [Entro]entro.securityagentic ai owasp researchThis creates a cascading risk where compromising one tool can…Read more…
This matters directly to the broader debate about AI bloom and humanity’s long-term future. Optimists imagine agents helping to accelerate science, manage infrastructure, reduce dangerous labour, and coordinate complex systems at unprecedented scale. But the same autonomy that could unlock abundance also creates new forms of fragility. A faulty agent connected to real-world systems may not merely produce a wrong answer. It may execute thousands of wrong actions at machine speed, spread errors across interconnected platforms, or amplify small failures into systemic disruption. Researchers and security organisations increasingly warn that the danger lies not only in more capable models, but in the combination of models with tools, memory, automation, and authority. [Apiiro]apiiro.comWhat Is Agentic AI Security?Why It Matters & Key RisksAgentic AI security refers to the principles, practices, and controls used to govern and safeguard AI systems t… [Entro]entro.securityagentic ai owasp researchThis creates a cascading risk where compromising one tool can…Read more…
What changes when agents control tools
Traditional software usually behaves in relatively predictable ways. A spreadsheet, database, or script may fail, but its behaviour is constrained by explicit rules. Modern AI agents are different because they combine flexible reasoning with operational access.
A typical agent may have access to:
- web browsers,
- APIs,
- email systems,
- code execution tools, [firecrawl.dev]firecrawl.devLearn how to design reliable tools and orchestrate themAgent Tools: Building Effective Capabilities for AI Systems30 Jan 2026 — Discover the 9 core categories of AI agent tools, from web searc…
- cloud infrastructure,
- internal company documents,
- scheduling systems,
- customer databases,
- or robotic devices.
Instead of a person manually reviewing every step, the agent may plan and execute long chains of actions autonomously. The danger is not only that the model makes mistakes, but that mistakes become operational.
A hallucinated answer inside a chatbot conversation is usually recoverable. A hallucinated command executed against a production server, payment system, or procurement workflow may not be. OWASP, the widely used web security organisation, now lists prompt injection and insecure output handling among the top risks for large language model applications because model outputs increasingly trigger real-world actions. [OWASP Gen AI Security Project]genai.owasp.orgllm01 prompt injectionOWASP Gen AI Security ProjectLLM01:2025 Prompt Injection - OWASP Gen AI Security ProjectPrompt injection involves manipulating model resp… [OWASP]owasp.orgOWASPOWASP Top 10 for Large Language Model ApplicationsOWASP Top 10 for Large Language Model Applications version 1.1 · LLM01: Prompt Inj…
The underlying architecture also matters. Modern agents are rarely a single model. They are ecosystems of components:
- orchestration software,
- memory layers,
- third-party plugins, [improving.com]improving.comOWASP Top 10 for LLMs: A Practitioner's Implementation…1 day ago — An application uses a third-party MCP server for document processing…
- external APIs,
- retrieval systems,
- tool servers,
- cloud services,
- and sometimes other agents.
Each connection creates another failure surface. A model may behave safely in isolation while becoming dangerous once connected to tools with broad permissions.
Why cascading failures are different from ordinary software bugs
Most software failures remain relatively local. A bug in one subsystem may crash a service or corrupt a file, but the damage is often bounded. Cascading agent failures are different because the system can continue adapting, improvising, and propagating errors.
The defining feature is propagation.
One bad output can become the trusted input for another system. That second system may then trigger additional actions, generating a chain reaction across platforms or organisations. Recent security literature on agentic AI repeatedly warns that interconnected tool chains make containment much harder. [Entro]entro.securityagentic ai owasp researchThis creates a cascading risk where compromising one tool can…Read more… [2Adversa AI |]adversa.aiAgentic AI SecurityCascading Failures in Agentic AI: Complete OWASP ASI08…A cascading failure in agentic AI occurs when a single fault…
Several characteristics make these failures unusually difficult to manage:
- Speed: agents can perform actions faster than humans can audit them.
- Scale: one operator may supervise dozens or thousands of agents.
- Persistence: agents can continue pursuing goals after initial errors.
- Opacity: long reasoning chains are difficult to inspect in real time.
- Cross-system reach: one workflow may touch finance, cloud systems, communications, and logistics simultaneously.
This creates a risk profile closer to automated financial flash crashes or tightly coupled infrastructure failures than to ordinary software glitches.
A common misconception is that catastrophic failures require malicious superintelligence. In reality, relatively mundane mistakes may be enough if the systems are deeply interconnected. An agent does not need intent to create large-scale disruption. It may simply optimise the wrong objective, misinterpret context, trust corrupted data, or follow manipulated instructions.
How prompt injection turns information into commands
One of the clearest examples of cascading risk is prompt injection. In ordinary computing, software usually distinguishes between executable instructions and untrusted data. Large language models do not reliably maintain that boundary.
This creates a fundamental vulnerability. Hidden instructions embedded inside web pages, emails, documents, or tool outputs can influence agent behaviour. Security researchers increasingly describe this as the AI equivalent of SQL injection attacks. [OWASP Gen AI Security Project]genai.owasp.orgllm01 prompt injectionOWASP Gen AI Security ProjectLLM01:2025 Prompt Injection - OWASP Gen AI Security ProjectPrompt injection involves manipulating model resp… [OWASP]genai.owasp.orgllm01 prompt injectionOWASP Gen AI Security ProjectLLM01:2025 Prompt Injection - OWASP Gen AI Security ProjectPrompt injection involves manipulating model resp…
[An indirect prompt injection attack might work like this:]genai.owasp.orgllm01 prompt injectionOWASP Gen AI Security ProjectLLM01:2025 Prompt Injection - OWASP Gen AI Security ProjectPrompt injection involves manipulating model resp…
- An agent browses a webpage or opens a document.
- Hidden text instructs the model to ignore prior rules.
- The agent interprets the malicious content as valid instructions.
- The agent retrieves sensitive information or executes unauthorised actions.
- The compromised outputs spread into connected systems.
The danger becomes much greater once agents have permissions to act.
A compromised browser agent might:
- send emails,
- exfiltrate internal documents,
- alter cloud configurations,
- trigger financial transactions,
- or poison downstream databases.
The UK National Cyber Security Centre has warned that prompt injection may never be fully solved because current large language models fundamentally blur the distinction between instructions and data. [TechRadar]techradar.comAccording to David C, Technical Director for Platforms Research at the NCSC, these attacks—where malicious instructions are embedded with…
That warning matters because the optimistic AI bloom vision depends heavily on agents interacting with enormous volumes of real-world information. Systems designed to accelerate science, automate administration, or coordinate infrastructure may necessarily consume untrusted external inputs. The more connected and autonomous these systems become, the more opportunities there are for manipulation to spread.
Where downstream failures can propagate
The most important insight about cascading failures is that the initial error may be relatively small. The larger danger lies in amplification across connected systems.
Software and cloud infrastructure
AI coding agents are already being used to write, test, and deploy software. This can improve productivity dramatically, but it also increases the risk of automated security mistakes propagating into production environments.
Researchers studying AI-assisted development tools have found major differences in how safely agents handle tool calls, hidden parameters, and prompt injection attacks. Some systems proved vulnerable to unauthorised tool use and cross-tool poisoning. [arXiv]arxiv.orgarXiv Are AI-assisted Development Tools Immune to Prompt Injection?arXivAre AI-assisted Development Tools Immune to Prompt Injection?March 23, 2026…
A flawed coding agent may:
- introduce insecure dependencies,
- expose credentials,
- delete production databases,
- deploy vulnerable code,
- or generate insecure cloud configurations.
Once automated deployment pipelines accept those outputs, the error can spread rapidly across entire infrastructure stacks.
Enterprise workflows
Many companies are experimenting with agents for procurement, scheduling, customer support, cybersecurity operations, and internal knowledge management.
These systems often have access to sensitive organisational tools. A single compromised workflow may therefore affect:
- payroll systems,
- contracts,
- customer data,
- internal communications,
- or supplier networks.
The risk is magnified when organisations allow agents to chain actions together automatically. One tool call may trigger another system, which triggers another, creating long execution paths that few humans fully understand.
Financial systems
Financial markets already demonstrate how tightly coupled automated systems can produce runaway failures. AI agents may increase this coupling further.
A trading or treasury-management agent that misinterprets market conditions could trigger automated sell orders, liquidity movements, or procurement decisions across multiple systems simultaneously. Even if safeguards prevent extreme outcomes, smaller disruptions may still propagate widely through highly connected institutions.
The concern is not only fraud or cyberattack. It is also correlated behaviour. If many firms rely on similar models trained on similar data, they may make similar mistakes at the same time.

Logistics and physical infrastructure
Future AI bloom scenarios often rely on autonomous logistics and robotics. Warehouses, ports, factories, delivery systems, and energy grids could become increasingly AI-coordinated.
That may greatly increase efficiency. It may also create tightly interconnected operational dependencies.
A planning error in one system could produce:
- inventory shortages,
- delivery failures,
- warehouse congestion,
- or infrastructure bottlenecks that spread geographically.
Physical systems are especially difficult because errors can create material consequences before humans intervene.
Multi-agent systems create new failure dynamics
Some of the most concerning scenarios involve networks of agents interacting with one another.
Instead of a single AI system making decisions, future environments may contain:
- procurement agents,
- cybersecurity agents,
- scheduling agents,
- scientific research agents,
- financial agents,
- and negotiation agents communicating continuously.
This can create emergent behaviour that no individual operator explicitly designed.
Security researchers studying multi-agent environments warn that corrupted information may propagate rapidly between agents that implicitly trust one another. [GitHub]github.com07 safety and governance.mdGalileo AI simulated cascading failures in multi-agent systems and found that a…Read more…
The analogy is partly biological and partly economic. Cascading failures can resemble:
- epidemics spreading through connected networks,
- financial contagion,
- or infrastructure blackouts.
A failure may remain invisible at first because each individual step appears reasonable in isolation. The overall system only becomes visibly unstable after many interacting actions accumulate.
This matters for the long-term AI bloom vision because many optimistic futures assume dense coordination between autonomous systems. A civilisation run partly through machine-to-machine delegation could become extraordinarily productive while also becoming vulnerable to rapid systemic failures if alignment, verification, and governance lag behind capability growth.
Why “human in the loop” often breaks down
Many organisations respond to these concerns by promising that humans remain “in the loop”. In practice, that safeguard may weaken as systems become faster and more complex.
There are several reasons.
First, human operators may become overwhelmed. A person supervising hundreds of agent actions cannot meaningfully audit every decision.
Second, automation bias is powerful. People tend to trust systems that appear competent most of the time. Once agents become reliable enough in routine situations, humans may stop carefully checking outputs.
Third, intervention may arrive too late. An agent operating at machine speed can complete thousands of actions before a human notices something is wrong.
Finally, the chains themselves become difficult to interpret. Modern agent workflows may involve dozens of intermediate steps spread across APIs, memory systems, external documents, and tool outputs. By the time a visible failure appears, the original source of the error may be hard to reconstruct.
These problems already exist in algorithmic trading, industrial automation, and cybersecurity response systems. Agentic AI may intensify them because the systems are more flexible and less predictable than traditional deterministic software.

How permissions and interruption points reduce harm
The emerging consensus among many security researchers is that powerful agents should be treated less like ordinary software and more like potentially unreliable operators with restricted privileges.
That shifts the focus from trying to make models perfectly safe toward limiting how much damage failures can cause.
Several safeguards recur across the literature.
Narrow permissions
Agents should receive the minimum access necessary for a task.
A research assistant agent does not necessarily need permission to:
- execute arbitrary code,
- send external emails,
- modify production systems,
- or access sensitive credentials.
Limiting permissions reduces the blast radius when failures occur.
Sandboxing and isolation
Many researchers recommend isolating agents from critical infrastructure wherever possible.
For example:
- code execution can occur in temporary environments,
- browser agents can run without logged-in credentials,
- and sensitive systems can require separate authorisation layers.
This resembles traditional cybersecurity compartmentalisation.
Human approval gates
High-risk actions can require explicit human confirmation.
Examples include:
- financial transfers,
- production deployments,
- deletion operations,
- external communications,
- or access to confidential records.
This slows the system down, but it creates interruption points where cascading chains can be halted.
Auditability and provenance tracking
Researchers increasingly emphasise provenance: tracing where instructions originated and how they influenced later decisions. [arXiv]arxiv.orgarXiv Are AI-assisted Development Tools Immune to Prompt Injection?arXivAre AI-assisted Development Tools Immune to Prompt Injection?March 23, 2026…
Without detailed logs, organisations may struggle to determine:
- why an agent acted,
- which external source influenced it,
- or how a failure spread.
Auditability becomes especially important in multi-agent environments.
Treating outputs as untrusted
One of the most important cultural shifts is recognising that model outputs should often be treated as untrusted inputs.
That sounds counterintuitive because agents are designed to automate reasoning. But security researchers increasingly argue that unrestricted trust in agent outputs is itself dangerous. OWASP [TechRadar]techradar.comAccording to David C, Technical Director for Platforms Research at the NCSC, these attacks—where malicious instructions are embedded with…
The tension inside the AI bloom vision
The deeper tension is that many of the most transformative AI bloom scenarios depend on exactly the forms of autonomy that create cascading risk.
A system capable of accelerating science, coordinating supply chains, managing energy grids, or automating large parts of civilisation must necessarily:
- interact with external systems,
- make decisions with limited supervision,
- and operate at scales beyond direct human monitoring.
That creates a structural trade-off.
The more constrained and interruptible agents are, the safer they may become, but the less transformative they may also be. Conversely, systems granted broad autonomy may unlock major economic and scientific gains while also creating new forms of systemic fragility.
This does not mean large-scale AI coordination is impossible. It means the governance challenge becomes central rather than peripheral. The long-term success of advanced AI may depend not only on intelligence itself, but on institutional design, verification systems, permission structures, monitoring tools, and resilient human oversight.
In that sense, cascading action chains are not merely a technical problem. They are a preview of a broader civilisational question: whether humanity can safely build systems powerful enough to coordinate and accelerate large parts of the world without allowing small failures to spread uncontrollably through the very networks meant to create abundance and flourishing.
Endnotes
-
Source: apiiro.com
Title: What Is Agentic AI Security?
Link: https://apiiro.com/glossary/agentic-ai-security/Source snippet
Why It Matters & Key RisksAgentic AI security refers to the principles, practices, and controls used to govern and safeguard AI systems t...
-
Source: entro.security
Title: agentic ai owasp research
Link: https://entro.security/blog/agentic-ai-owasp-research/Source snippet
This creates a cascading risk where compromising one tool can...Read more...
-
Source: owasp.org
Link: https://owasp.org/www-project-top-10-for-large-language-model-applications/Source snippet
OWASPOWASP Top 10 for Large Language Model ApplicationsOWASP Top 10 for Large Language Model Applications version 1.1 · LLM01: Prompt Inj...
-
Source: genai.owasp.org
Title: llm01 prompt injection
Link: https://genai.owasp.org/llmrisk/llm01-prompt-injection/Source snippet
OWASP Gen AI Security ProjectLLM01:2025 Prompt Injection - OWASP Gen AI Security ProjectPrompt injection involves manipulating model resp...
-
Source: adversa.ai
Link: https://adversa.ai/blog/cascading-failures-in-agentic-ai-complete-owasp-asi08-security-guide-2026/Source snippet
Agentic AI SecurityCascading Failures in Agentic AI: Complete OWASP ASI08...A cascading failure in agentic AI occurs when a single fault...
-
Source: owasp.org
Link: https://owasp.org/www-community/attacks/PromptInjectionSource snippet
Prompt InjectionPrompt Injection is a novel security vulnerability that targets Large Language Models (LLMs) like ChatGPT, Bard, and othe...
-
Source: techradar.com
Link: https://www.techradar.com/pro/security/prompt-injection-attacks-might-never-be-properly-mitigated-uk-ncsc-warnsSource snippet
According to David C, Technical Director for Platforms Research at the NCSC, these attacks—where malicious instructions are embedded with...
-
Source: arxiv.org
Title: arXiv Are AI-assisted Development Tools Immune to Prompt Injection?
Link: https://arxiv.org/abs/2603.21642Source snippet
arXivAre AI-assisted Development Tools Immune to Prompt Injection?March 23, 2026...
Published: March 23, 2026
-
Source: github.com
Title: 07 safety and governance.md
Link: https://github.com/ombharatiya/ai-system-design-guide/blob/main/17-tool-use-and-computer-agents/07-safety-and-governance.mdSource snippet
Galileo AI simulated cascading failures in multi-agent systems and found that a...Read more...
-
Source: arxiv.org
Title: arXiv ARGUS: Defending LLM Agents Against Context-Aware Prompt Injection
Link: https://arxiv.org/abs/2605.03378Source snippet
arXivARGUS: Defending LLM Agents Against Context-Aware Prompt InjectionMay 5, 2026...
Published: May 5, 2026
-
Source: arxiv.org
Link: https://arxiv.org/abs/2604.24118 -
Source: owasp.org
Link: https://owasp.org/Source snippet
OWASP Foundation, the Open Source Foundation for...Explore the world of cyber security. Driven by volunteers, OWASP resources are access...
-
Source: cheatsheetseries.owasp.org
Title: LLM Prompt Injection Prevention Cheat Sheet
Link: https://cheatsheetseries.owasp.org/cheatsheets/LLM_Prompt_Injection_Prevention_Cheat_Sheet.htmlSource snippet
Prompt Injection Prevention Cheat SheetPrompt injection is a vulnerability in Large Language Model (LLM) applications that allows attacke...
-
Source: arxiv.org
Link: https://arxiv.org/html/2601.05293v1Source snippet
A Survey of Agentic AI and Cybersecurity8 Jan 2026 — Agentic AI extends cybersecurity beyond traditional, alert-driven detection systems...
-
Source: arxiv.org
Link: https://arxiv.org/html/2603.06847v1Source snippet
Characterizing Faults in Agentic AI: A Taxonomy of Types...6 Mar 2026 — This fault can lead to failures such as rejected API calls, inc...
-
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/OWASPSource snippet
OWASPOWASP, the Open Worldwide Application Security Project is an online community that publishes open-source information and resource...
-
Source: trendmicro.com
Title: owasp top 10
Link: https://www.trendmicro.com/en_us/what-is/ai/owasp-top-10.htmlSource snippet
The OWASP Top 10 for LLMs warns of risks like prompt injection, data leakage, and insecure plugins.Read more...
-
Source: trendmicro.com
Title: owasp top 10
Link: https://www.trendmicro.com/en/what-is/ai/owasp-top-10.htmlSource snippet
What are the OWASP Top 10 risks for LLMs?5 Feb 2026 — Monitor Outputs for Sensitive Data: Use automated tools to detect and redact confid...
-
Source: blog.alexewerlof.com
Title: owasp top 10 ai llm agents
Link: https://blog.alexewerlof.com/p/owasp-top-10-ai-llm-agentsSource snippet
Top 10 Agents & AI Vulnerabilities (2026 Cheat...10 Mar 2026 — A pragmatic engineering guide and cheat sheet for the OWASP Top 10 AI, OW...
-
Source: improving.com
Link: https://www.improving.com/es-mx/thoughts/owasp-top-10-llm-security-guide/Source snippet
OWASP Top 10 for LLMs: A Practitioner's Implementation...1 day ago — An application uses a third-party MCP server for document processing...
-
Source: aembit.io
Title: owasp top 10 llm risks explained
Link: https://aembit.io/blog/owasp-top-10-llm-risks-explained/Source snippet
OWASP Top 10 for LLM Applications (2025)Learn what's new in the OWASP Top 10 for LLM Applications 2025, including prompt injection, exces...
-
Source: owasptopten.org
Link: https://www.owasptopten.org/Source snippet
The OWASP Top Ten 2025The OWASP Top Ten is a standard awareness document for developers and web application security. It represents a bro...
Additional References
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/thescholarbaniya_how-can-you-prevent-ai-agent-failures-4-activity-7452212040242315264-hbdgSource snippet
4 AI Security Layers to Prevent Agent FailuresMost AI agent failures won't come from the model—they'll come from identity gaps, dirty mem...
-
Source: wired.com
Link: https://www.wired.com/story/generative-ai-prompt-injection-hackingSource snippet
These indirect prompt injection attacks, originating from third-party sources like websites or PDFs, are a growing concern in cybersecuri...
-
Source: linkedin.com
Link: https://www.linkedin.com/top-content/artificial-intelligence/ai-safety-and-risk-management/key-risks-of-agentic-ai-systems/Source snippet
Key Risks of Agentic AI SystemsThe key risks of agentic AI systems include vulnerabilities that can lead to unintended consequences, secu...
-
Source: paloaltonetworks.com
Link: https://www.paloaltonetworks.com/cyberpedia/agentic-ai-security-solutionsSource snippet
Agentic AI Security Solutions: Top 7 Platforms ComparedAgentic AI security solutions protect autonomous AI systems that plan, reason, and...
-
Source: tao-hpu.medium.com
Title: agent security boundaries from prompt injection to tool misuse d25b6dbaad60
Link: https://tao-hpu.medium.com/agent-security-boundaries-from-prompt-injection-to-tool-misuse-d25b6dbaad60Source snippet
Security Boundaries: From Prompt Injection to Tool...Prompt injection ranks as the top vulnerability in OWASP's Top 10 for LLM Applicati...
-
Source: rippling.com
Title: Learn how to secure autonomous AI agents and implement robust
Link: https://www.rippling.com/blog/agentic-ai-securitySource snippet
Agentic AI Security: A Guide to Threats, Risks & Best...26 Sept 2025 — Comprehensive guide to agentic AI security threats, risks, and be...
-
Source: manh.com
Title: the autonomy paradox why true ai agents require rigid rules
Link: https://www.manh.com/en-gb/our-insights/resource-types/blog/the-autonomy-paradox-why-true-ai-agents-require-rigid-rulesSource snippet
The Autonomy Paradox: Why True AI Agents Require Rigid...24 Apr 2026 — Learn how agentic AI, LLMs, and enterprise automation work togeth...
-
Source: firecrawl.dev
Title: Learn how to design reliable tools and orchestrate them
Link: https://www.firecrawl.dev/blog/agent-toolsSource snippet
Agent Tools: Building Effective Capabilities for AI Systems30 Jan 2026 — Discover the 9 core categories of AI agent tools, from web searc...
-
Source: dev.to
Title: preventing cascading failures in ai agents p3c
Link: https://dev.to/willvelida/preventing-cascading-failures-in-ai-agents-p3cSource snippet
Preventing Cascading Failures in AI Agents13 Mar 2026 — Each tool call involves a chain: agent → APIM → health data API → Cosmos DB → bac...
-
Source: securance.com
Title: prompt injection the owasp 1 ai threat in 2026
Link: https://www.securance.com/blog/prompt-injection-the-owasp-1-ai-threat-in-2026/Source snippet
Prompt injection: the OWASP #1 AI threat in 2026Prompt injection is a cyberattack technique that manipulates large language models (LLMs)...
Amazon book picks
Further Reading
Books and field guides related to Cascading action chains. Use these as the next step if you want deeper reading beyond the article.

Introduction to AI Safety, Ethics, and Society
As AI technology is rapidly progressing in capability and being adopted more widely across society, it is more important than ever to und...

AI Safety and Preventing Harm in AI Systems
As AI systems become increasingly embedded in all facets of society from healthcare and finance to transportation and public services, en...

Artificial Intelligence Safety and Security
The history of robotics and artificial intelligence in many ways is also the history of humanity’s attempts to control such technologies....

Intelligent autonomous systems
First published 2010. Subjects: Intelligent agents (Computer software), Artificial intelligence, Intelligent control systems, Intelligent...
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.

Example eBay listing
A.I. Artificial Intelligence Original Movie Poster Signed By Jude Law
USD 125.00 | Shipping USD 25.00 | US

Example eBay listing
Artificial Intelligence D/S Original Movie Poster - 27 x 40"
USD 19.50 | Shipping USD 13.65 | US

Example eBay listing
612388 Artificial Intelligence Movie Science Fiction Drama Wall Print Poster
USD 22.95 | Shipping USD 12.95 | JP

Example eBay listing
Companion - Artificial Intelligence Dark Comedy Cinema Film - POSTER 20"x30"
USD 23.99 | Free shipping | US
Topic Tree