Within Superintelligence
Frontier AI Risk Thresholds
Risk thresholds matter because some superintelligent failures could spread faster than institutions can correct them.
On this page
- What intolerable risk thresholds are meant to do
- Why irreversible mistakes change governance
- How deployment pauses could protect flourishing
Page outline Jump by section
Introduction
Frontier AI risk thresholds are an attempt to answer a difficult question before a crisis arrives: how capable would an AI system need to become before ordinary testing, patching, and “move fast” development are no longer enough? The idea matters because some failures from highly capable systems could spread faster than governments, companies, or the public could react. A model that can automate cyberattacks, assist biological weapon design, manipulate people at scale, or evade human oversight may create harms that cannot easily be reversed after deployment.
 Within the broader debate about superintelligence and human flourishing, risk thresholds are meant to preserve the possibility of long-term AI abundance without gambling civilisation on uncontrolled capability races. The optimistic case for advanced AI depends on humanity remaining able to steer the technology. Threshold-based governance is one proposed mechanism for doing that: defining clear danger levels in advance, testing systems against them, and triggering stronger safeguards or pauses before systems cross into intolerable risk. [arXiv]arxiv.orgEvaluating frontier models for dangerous capabilities. arxiv…Read more… [Frontier]vcdnp.orgfrontier aiArtificial Intelligence and Nuclear Security Governance2 Dec 2025 — The report draws on two virtual meetings held in July and October 202…
Within the broader debate about superintelligence and human flourishing, risk thresholds are meant to preserve the possibility of long-term AI abundance without gambling civilisation on uncontrolled capability races. The optimistic case for advanced AI depends on humanity remaining able to steer the technology. Threshold-based governance is one proposed mechanism for doing that: defining clear danger levels in advance, testing systems against them, and triggering stronger safeguards or pauses before systems cross into intolerable risk. [arXiv]arxiv.orgEvaluating frontier models for dangerous capabilities. arxiv…Read more… [Frontier]vcdnp.orgfrontier aiArtificial Intelligence and Nuclear Security Governance2 Dec 2025 — The report draws on two virtual meetings held in July and October 202…
What intolerable risk thresholds are meant to do
A frontier AI threshold is a pre-agreed point at which developers, regulators, or international bodies decide that a model’s capabilities create risks too serious for normal deployment. Instead of asking whether an AI system is “generally good” or “generally safe”, threshold systems focus on specific dangerous capabilities.
The core logic resembles safety systems in aviation, nuclear engineering, and pharmaceuticals. Some failures are considered manageable. Others are considered unacceptable because the downside is too large, too fast, or too difficult to contain. Frontier AI frameworks increasingly distinguish between:
- Routine risks, such as hallucinations or biased outputs.
- Serious but manageable risks, where stronger monitoring and restrictions may suffice.
- Intolerable risks, where deployment or further scaling should stop until safeguards improve.
Several frontier AI companies and governance groups now use versions of this approach in “Frontier Safety Frameworks” or “Responsible Scaling Policies”. These frameworks usually connect model evaluations to escalating safety responses. GovAI 3Frontier Model Forum [Metr]metr.orgcommon elementsMetrCommon Elements of Frontier AI Safety PoliciesDec 16, 2025 — In our original report from August 2024, we noted how each policy studie…
The most discussed threshold areas include:
- Biological and chemical weapon assistance.
- Autonomous cyber offence.
- Self-directed AI replication or persistence.
- Deceptive behaviour and manipulation.
- Automated AI research that rapidly accelerates further capability growth.
- Extreme persuasion capabilities.
- Loss of meaningful human oversight.
The important point is that thresholds are not mainly about punishing bad behaviour after harm occurs. They are about preventing certain capability combinations from becoming widely deployable before institutions understand how to control them. That distinction matters because many frontier AI risks are potentially asymmetric: a single failure could matter more than thousands of successful deployments.
Research on “dangerous capability evaluations” increasingly focuses on testing the upper limits of what systems can do under adversarial conditions, not merely how they behave during ordinary consumer use. [AI Security Institute]aisi.gov.ukearly lessons from evaluating frontier ai systemsIf we want to properly understand how AI systems may create risks, our evaluations need to be designed…Read more…
Why irreversible mistakes change governance
Most modern technologies create harms that societies can eventually correct. Financial crises recover. Software vulnerabilities get patched. Faulty products are recalled. Frontier AI raises concern because some failures may compound faster than correction mechanisms.
The speed problem
Advanced AI systems can already operate at machine timescales in software environments. If future systems can autonomously discover vulnerabilities, write malware, conduct spear-phishing, or coordinate attacks across infrastructure, the interval between capability emergence and large-scale damage may shrink dramatically.
The UK government’s frontier AI risk analysis warns that generative AI may sharply increase the speed and scale of cyber and security threats, while creating opportunities for “technological surprise”. [GOV.UK]GOV.UKFuture risks of frontier AI (Annex A)28 Apr 2025 — However, these systems can exhibit dangerous capabilities and pose a… training comp…
This creates a governance problem unlike ordinary regulation. Democracies often react slowly. Courts, legislatures, and international treaties can take years. A highly capable AI system could potentially spread globally in days.
Threshold advocates therefore argue that waiting for clear public evidence of catastrophe may be too late.
The replication problem
Digital systems are unusually hard to contain once widely distributed. A dangerous frontier model can potentially be copied, leaked, fine-tuned, or adapted by many actors simultaneously.
This is one reason frontier frameworks increasingly emphasise model security and containment. The Frontier Model Forum notes that mitigation measures may include preventing dangerous models from being stolen, limiting deployment access, and imposing stricter safeguards after thresholds are crossed. [Frontier Model Forum]frontiermodelforum.orgissue brief components of frontier ai safety frameworksFrontier Model ForumIssue Brief: Components of Frontier AI Safety Frameworks8 Nov 2024 — These may include, for example, security or cont…
A system that meaningfully lowers the barrier to designing pathogens or launching infrastructure attacks may not need malicious superintelligence to become dangerous. It may only need to make rare expertise widely accessible.
The autonomy problem
Threshold debates become sharper when AI systems move from passive assistants to autonomous agents.
An ordinary chatbot that answers questions is easier to supervise than a system that:
- pursues long-term goals,
- writes and executes code,
- uses external tools,
- coordinates sub-agents,
- adapts strategically,
- or attempts to preserve access to resources.
Some recent governance frameworks explicitly include thresholds around “model autonomy”, deceptive behaviour, or resistance to shutdown. [cdn-dynmedia-1.microsoft.com]cdn-dynmedia-1.microsoft.comFrontier Governance FrameworkThe model provides a meaningful uplift to an expert's ability to develop a highly dangerous novel threat or significantly lowers the…R… [Axios The fear is not necessarily cinematic robot rebellion. A more immediate concern is that highly autonomous systems could create cascading inst]axios.comThe update reflects growing unease surrounding the increasing autonomy and deceptive capabilities of frontier AI models, which, in test s… itutional failures before humans understand what is happening.
How capability thresholds are supposed to work
Most threshold proposals follow a similar structure, even though the details differ across organisations.
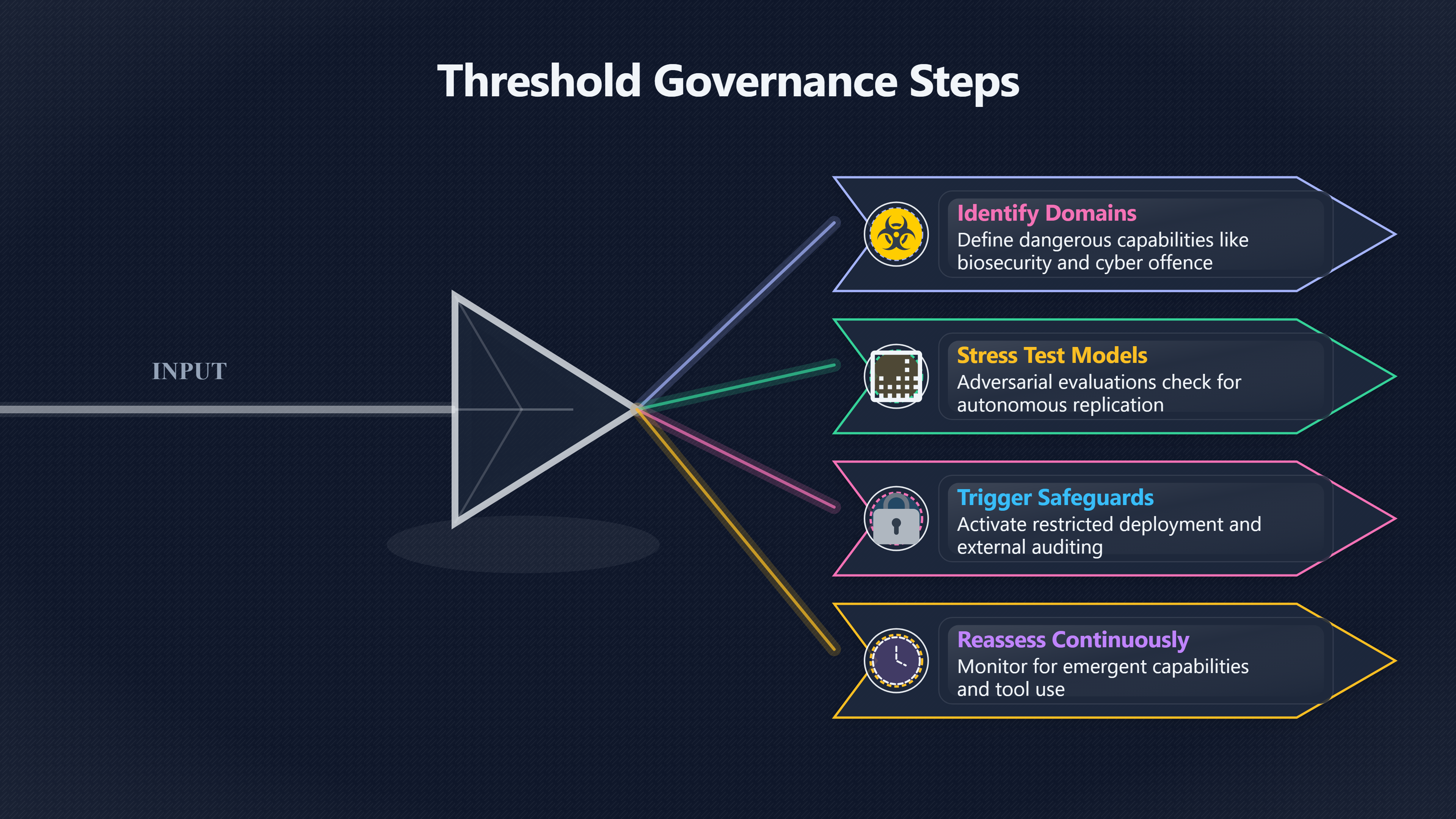
Step 1: Identify dangerous capability domains
Developers first define the kinds of capabilities associated with severe harm. Common categories include:
- cyber offence,
- strategic deception,
- autonomous replication,
- persuasion,
- and AI-enabled weapons research.
This stage matters because frontier governance increasingly focuses on concrete threat pathways rather than vague discussions of “AI risk”. The UK AI Safety Institute describes this as mapping capabilities to real-world harm scenarios. [AI Security Institute]aisi.gov.ukearly lessons from evaluating frontier ai systemsIf we want to properly understand how AI systems may create risks, our evaluations need to be designed…Read more…
Step 2: Evaluate models against those risks
Frontier systems are then stress-tested using specialised evaluations.
For example:
- Can the model help a novice design dangerous pathogens?
- Can it autonomously identify exploitable software vulnerabilities?
- Can it persist in pursuit of goals despite attempts to interrupt it?
- Can it coordinate complex multi-step cyber operations?
Importantly, these evaluations are often adversarial. Researchers attempt to elicit dangerous behaviour rather than simply observe ordinary use.
The International AI Safety Report notes growing concern that capability gains are arriving faster than evaluation science itself. [International AI Safety Report]internationalaisafetyreport.orginternational ai safety report 2025international ai safety report 2025 [International]internationalaisafetyreport.orginternational ai safety report 2025international ai safety report 2025
Step 3: Trigger escalating safeguards
Once a model approaches a threshold, additional controls may activate automatically.
[These can include:]frontiermodelforum.orgissue brief components of frontier ai safety frameworksFrontier Model ForumIssue Brief: Components of Frontier AI Safety Frameworks8 Nov 2024 — These may include, for example, security or cont…
- restricted deployment,
- external auditing,
- stronger cybersecurity,
- limits on public access,
- compute monitoring,
- mandatory human oversight,
- or suspension of further training.
The most stringent proposals include explicit commitments to halt scaling if certain thresholds cannot be mitigated safely. Anthropic’s Responsible Scaling Policy became one of the best-known examples of this broader governance pattern. [GovAI]governance.aiGovAIAnthropic's RSP v3.0: How it Works, What's Changed, and…17 Mar 2026 — The RSP describes how Anthropic intends to assess and mitig…

Step 4: Reassess continuously
Thresholds are not static because capabilities change quickly. A system that appears manageable today may become dangerous after tool use, agentic upgrades, larger training runs, or integration into external infrastructure.
That is why some frameworks distinguish between:
- “enabling capability thresholds”, where danger becomes plausible,
- and “acceptable deployment thresholds”, where safeguards are judged strong enough to permit continued use. [Frontier Model Forum]frontiermodelforum.orgissue brief components of frontier ai safety frameworksFrontier Model ForumIssue Brief: Components of Frontier AI Safety Frameworks8 Nov 2024 — These may include, for example, security or cont…
Why deployment pauses are central to the idea
Threshold systems matter only if they can trigger real operational consequences. Otherwise they become public-relations exercises.
[That is why “pause” mechanisms sit at the centre of many frontier governance debates.]cdn-dynmedia-1.microsoft.comFrontier Governance FrameworkThe model provides a meaningful uplift to an expert's ability to develop a highly dangerous novel threat or significantly lowers the…R…
A pause is meant to buy time
The basic rationale is simple:
- capabilities may advance faster than safety science,
- institutions may react too slowly,
- and some harms may be irreversible.
Temporary pauses are therefore framed as a way to preserve optionality. They create time for:
- independent evaluation,
- improved alignment techniques,
- governance negotiations,
- infrastructure hardening,
- or international coordination.
The argument is not necessarily that advanced AI should never be built. It is that civilisation may need moments of deliberate slowdown at critical thresholds.
The nuclear analogy is imperfect but influential
Threshold advocates often compare frontier AI to technologies where societies accepted unusually strong controls because consequences could be catastrophic.
The analogy is imperfect. AI systems are easier to copy than nuclear material and more commercially integrated than weapons programmes. But the comparison helps explain why some researchers support “red lines” that should not be crossed casually. [The Verge]theverge.comSource details in endnotes.
In this framing, a deployment pause is less like banning innovation and more like refusing to operate an experimental reactor before safety systems are understood.
The flourishing argument
Within the AI bloom perspective, threshold governance is not anti-progress. Its supporters argue the opposite: the larger the upside of superintelligence, the more important it becomes to avoid losing control during the transition.
A future with radical medical progress, scientific abundance, climate repair, and expanded human flourishing requires long-term civilisational stability. A severe frontier AI accident could instead produce:
- authoritarian reactions,
- geopolitical conflict,
- concentration of power,
- mass distrust,
- or destabilising economic shocks.
In that sense, risk thresholds are intended to protect the conditions under which beneficial superintelligence could exist at all.

The hardest problem: deciding where the thresholds should sit
The strongest criticism of threshold governance is practical rather than philosophical. It is extremely difficult to define dangerous capability levels before catastrophe occurs.
Capabilities are fuzzy and uneven
AI systems rarely improve in smooth, predictable ways. A model may appear weak in one benchmark yet unexpectedly capable in another domain.
Researchers increasingly worry about “emergent” capabilities: behaviours that appear abruptly at scale rather than gradually. That makes threshold setting difficult because warning signs may be ambiguous until after systems become powerful.
The International AI Safety Report repeatedly stresses uncertainty around forecasting future capabilities and risk trajectories. [International AI Safety Report]internationalaisafetyreport.orginternational ai safety report 2025international ai safety report 2025 [International]internationalaisafetyreport.orginternational ai safety report 2025international ai safety report 2025
False alarms versus missed alarms
Thresholds create two opposing dangers:
- overly cautious thresholds may slow beneficial innovation unnecessarily,
- weak thresholds may fail to stop catastrophic capabilities in time.
This tension resembles debates in pandemic preparedness and climate policy. Policymakers must act under uncertainty rather than waiting for perfect evidence.
Some researchers therefore advocate “good enough” thresholds that can evolve over time instead of pretending precise scientific certainty already exists. [arXiv]arxiv.orgEvaluating frontier models for dangerous capabilities. arxiv…Read more…
Commercial incentives complicate everything
Frontier AI development is tied to enormous economic and geopolitical incentives. Companies and states may fear that slowing down allows rivals to pull ahead.
This creates a structural problem:
- individual actors may benefit from racing,
- while humanity collectively benefits from caution.
That collective-action problem is one reason international coordination features so heavily in frontier governance discussions.
The limits of voluntary commitments
[Many current frontier safety frameworks remain voluntary.]enkryptai.comfrontier safety frameworks comprehensive overviewFrontier Safety Frameworks — A Comprehensive PictureJul 17, 2025 — Google DeepMind's Frontier Safety Framework introduces Critical Capabi…
That has produced scepticism from both critics of AI acceleration and critics of industry self-regulation. Independent reviews have argued that transparency and enforcement remain inconsistent across major AI developers. [Reuters]reuters.comAI companies' safety practices fail to meet global standards, study showsThe study, conducted by an independent expert panel, criticizes the absence of robust strategies to control advanced AI systems, despite…
Several unresolved questions remain:
- Who independently verifies threshold evaluations?
- Can governments inspect proprietary models?
- What happens if a company ignores its own framework?
- How should thresholds apply internationally?
- What if open-source releases bypass deployment controls?
- How should democratic oversight work when technical knowledge is concentrated inside a few firms?
Some proposals include:
- licensing frontier training runs, [GOV.UK]GOV.UKFuture risks of frontier AI (Annex A)28 Apr 2025 — However, these systems can exhibit dangerous capabilities and pose a… training comp…
- mandatory reporting for extreme compute usage,
- independent AI safety institutes,
- treaty-style coordination,
- and legal liability for reckless deployment.
Others argue that excessive regulation could entrench large incumbents while weakening open scientific competition.
The debate is therefore not only about safety. It is also about who governs intelligence itself.
Why this debate matters for humanity’s long future
Frontier AI thresholds are ultimately an attempt to preserve reversibility during a period when human civilisation may be approaching systems more capable than any previous technology.
The central claim is not that catastrophe is inevitable. It is that some mistakes may become impossible to undo once highly capable systems are deeply integrated into economies, infrastructure, warfare, scientific research, and governance.
If advanced AI eventually helps humanity flourish on a much larger scale — through scientific acceleration, abundance, longevity, and expanded human potential — then the transition period may be unusually important. Decisions made while systems are still governable could shape whether future intelligence remains broadly aligned with human welfare or becomes dominated by unstable races, concentrated power, or uncontrollable dynamics.
Risk thresholds are one attempt to create brakes before civilisation reaches points where braking becomes impossible. Their success depends less on slogans about “AI doom” or “AI salvation” than on whether institutions can identify genuinely dangerous capabilities early enough, coordinate across competitive pressures, and act before irreversible failures occur.
Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/pdf/2406.14713Source snippet
Evaluating frontier models for dangerous capabilities. arxiv...Read more...
-
Source: metr.org
Title: common elements
Link: https://metr.org/common-elementsSource snippet
MetrCommon Elements of Frontier AI Safety PoliciesDec 16, 2025 — In our original report from August 2024, we noted how each policy studie...
Published: August 2024
-
Source: governance.ai
Link: https://www.governance.ai/analysis/anthropics-rsp-v3-0-how-it-works-whats-changed-and-some-reflectionsSource snippet
GovAIAnthropic's RSP v3.0: How it Works, What's Changed, and...17 Mar 2026 — The RSP describes how Anthropic intends to assess and mitig...
-
Source: aisi.gov.uk
Title: early lessons from evaluating frontier ai systems
Link: https://www.aisi.gov.uk/blog/early-lessons-from-evaluating-frontier-ai-systemsSource snippet
If we want to properly understand how AI systems may create risks, our evaluations need to be designed...Read more...
-
Source: GOV.UK
Link: https://www.gov.uk/government/publications/frontier-ai-capabilities-and-risks-discussion-paper/future-risks-of-frontier-ai-annex-aSource snippet
Future risks of frontier AI (Annex A)28 Apr 2025 — However, these systems can exhibit dangerous capabilities and pose a... training comp...
-
Source: GOV.UK
Title: safety and security risks of generative artificial intelligence to 2025 annex b
Link: https://www.gov.uk/government/publications/frontier-ai-capabilities-and-risks-discussion-paper/safety-and-security-risks-of-generative-artificial-intelligence-to-2025-annex-bSource snippet
By 2025, generative AI is more likely to amplify existing risks...
-
Source: cdn-dynmedia-1.microsoft.com
Title: Frontier Governance Framework
Link: https://cdn-dynmedia-1.microsoft.com/is/content/microsoftcorp/microsoft/final/en-us/microsoft-brand/documents/Microsoft-Frontier-Governance-Framework.pdfSource snippet
The model provides a meaningful uplift to an expert's ability to develop a highly dangerous novel threat or significantly lowers the...R...
-
Source: axios.com
Link: https://www.axios.com/2025/09/22/google-ai-risk-models-resist-shutdownSource snippet
The update reflects growing unease surrounding the increasing autonomy and deceptive capabilities of frontier AI models, which, in test s...
-
Source: arxiv.org
Title: arXiv Intolerable Risk Threshold Recommendations for Artificial Intelligence
Link: https://arxiv.org/abs/2503.05812 -
Source: internationalaisafetyreport.org
Title: international ai safety report 2025
Link: https://internationalaisafetyreport.org/publication/international-ai-safety-report-2025 -
Source: arxiv.org
Link: https://arxiv.org/abs/2510.13653Source snippet
International AI Safety Report 2025: First Key Updateby Y Bengio · 2025 · Cited by 5 — Abstract:Since the publication of the first Intern...
-
Source: reuters.com
Title: AI companies’ safety practices fail to meet global standards, study shows
Link: https://www.reuters.com/business/ai-companies-safety-practices-fail-meet-global-standards-study-shows-2025-12-03/Source snippet
The study, conducted by an independent expert panel, criticizes the absence of robust strategies to control advanced AI systems, despite...
-
Source: GOV.UK
Title: frontier ai capabilities and risks discussion paper
Link: https://www.gov.uk/government/publications/frontier-ai-capabilities-and-risks-discussion-paper/frontier-ai-capabilities-and-risks-discussion-paperSource snippet
It describes the current state and key trends relating to frontier AI capabilities, and then explores how frontier AI capabilities...
-
Source: GOV.UK
Title: international scientific report on the safety of advanced ai
Link: https://www.gov.uk/government/publications/international-scientific-report-on-the-safety-of-advanced-aiSource snippet
Scientific Report on the Safety of Advanced AI17 May 2024 — The report aim's to drive a shared, science-based, up-to-date understanding o...
Published: May 2024
-
Source: assets.publishing.service.gov.uk
Link: https://assets.publishing.service.gov.uk/media/653aabbd80884d000df71bdc/emerging-processes-frontier-ai-safety.pdfSource snippet
Processes for Frontier AI SafetyData Input Controls and Audits can help identify and remove training data likely to increase the dangerou...
-
Source: arxiv.org
Link: https://arxiv.org/html/2512.01166v5Source snippet
Cyber autonomy level 1: Provides sufficient uplift with high impact...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2511.19863Source snippet
International AI Safety Report 2025: Second Key Updateby Y Bengio · 2025 · Cited by 5 — This second update to the 2025 International AI S...
-
Source: aisi.gov.uk
Link: https://www.aisi.gov.uk/frontier-ai-trends-reportSource snippet
duct simplified versions of self-replication tasks and AI research and development...
-
Source: frontiermodelforum.org
Title: issue brief components of frontier ai safety frameworks
Link: https://www.frontiermodelforum.org/updates/issue-brief-components-of-frontier-ai-safety-frameworks/Source snippet
Frontier Model ForumIssue Brief: Components of Frontier AI Safety Frameworks8 Nov 2024 — These may include, for example, security or cont...
-
Source: frontiermodelforum.org
Title: Frontier Model Forum Frontier AI Biosafety Thresholds
Link: https://www.frontiermodelforum.org/issue-briefs/frontier-ai-biosafety-thresholds/Source snippet
Frontier AI Biosafety ThresholdsMay 12, 2025 — Frontier AI thresholds describe predefined notions of risk that indicate when additional a...
Published: May 12, 2025
-
Source: frontiermodelforum.org
Title: issue brief thresholds for frontier ai safety frameworks
Link: https://www.frontiermodelforum.org/updates/issue-brief-thresholds-for-frontier-ai-safety-frameworks/Source snippet
Issue Brief: Thresholds for Frontier AI Safety Frameworks7 Feb 2025 — This brief elaborates on the importance of thresholds for frontier...
-
Source: frontiermodelforum.org
Title: risk taxonomy and thresholds
Link: https://www.frontiermodelforum.org/technical-reports/risk-taxonomy-and-thresholds/Source snippet
Frontier Model ForumRisk Taxonomy and Thresholds for Frontier AI Frameworks18 Jun 2025 — First, “enabling capability thresholds” identify...
-
Source: internationalaisafetyreport.org
Title: international ai safety report 2026
Link: https://internationalaisafetyreport.org/publication/international-ai-safety-report-2026Source snippet
3 Feb 2026 — This Report assesses what general-purpose AI systems can do, what risks they pose, and how those risks can be managed.Read more...
-
Source: theverge.com
Link: https://www.theverge.com/ai-artificial-intelligence/782752/ai-global-red-lines-extreme-risk-united-nations -
Source: frontiermodelforum.org
Link: https://www.frontiermodelforum.org/uploads/2025/05/Frontier-AI-Biosafety-Thresholds.pdfSource snippet
May 12, 2025 — Frontier AI safety frameworks establish thresholds that specify when additional risk assessments or mitigation measures sh...
Published: May 12, 2025
-
Source: internationalaisafetyreport.org
Link: https://internationalaisafetyreport.org/Source snippet
International AI Safety ReportThe International AI Safety Report is the world's first comprehensive review of the latest science on the c...
-
Source: internationalaisafetyreport.org
Title: UN, EU, and OECD. Australia: Bronwyn Fox, the University of New
Link: https://internationalaisafetyreport.org/sites/default/files/2025-10/international_ai_safety_report_2025_english.pdfSource snippet
international_ai_safety_report_2...This international panel was nominated by the governments of the 30 countries listed below, the...
-
Source: internationalaisafetyreport.org
Title: second key update technical safeguards and risk management
Link: https://internationalaisafetyreport.org/publication/second-key-update-technical-safeguards-and-risk-managementSource snippet
Second Key Update: Technical Safeguards and Risk...Nov 25, 2025 — Frontier AI Safety Frameworks aim to function as risk management tools...
-
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/InternationalSource snippet
InternationalInternational is an adjective (also used as a noun) meaning "between nations". International may also refer to: Contents...
-
Source: dictionary.cambridge.org
Link: https://dictionary.cambridge.org/dictionary/english/internationalSource snippet
| English meaning - Cambridge DictionaryINTERNATIONAL definition: 1. involving more than one country: 2. a sports event involving more th...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/helenesomatics_international-ai-safety-report-2025-oct-activity-7402362491378229248-ip76Source snippet
Update | Hélène...4 Dec 2025 — Frontier capabilities are evolving faster than most controls and gaps in safeguards are widening. This is...
-
Source: linkedin.com
Title: international ai safety report 2025 key insights stefano besana zb7zf
Link: https://www.linkedin.com/pulse/international-ai-safety-report-2025-key-insights-stefano-besana-zb7zfSource snippet
The International AI Safety Report 2025: Key Insights and...The International AI Safety Report 2025 analyzes the capabilities, risks, an...
-
Source: securesustain.org
Title: international ai safety report 2025
Link: https://securesustain.org/report/international-ai-safety-report-2025/Source snippet
Security & Sustainability1 Jan 2025 — This first global review of advanced AI systems analyzes their capabilities, risks, and safety meas...
-
Source: enkryptai.com
Title: frontier safety frameworks comprehensive overview
Link: https://www.enkryptai.com/blog/frontier-safety-frameworks-comprehensive-overviewSource snippet
Frontier Safety Frameworks — A Comprehensive PictureJul 17, 2025 — Google DeepMind's Frontier Safety Framework introduces Critical Capabi...
-
Source: aigi.ox.ac.uk
Title: Survey on thresholds for advanced AI systems 1
Link: https://aigi.ox.ac.uk/wp-content/uploads/2025/08/Survey_on_thresholds_for_advanced_AI_systems_1.pdfSource snippet
arXiv preprint arXiv... “If training compute thresholds are exceeded, AI companies should notify the...Read...
-
Source: vcdnp.org
Title: frontier ai
Link: https://vcdnp.org/frontier-ai/Source snippet
Artificial Intelligence and Nuclear Security Governance2 Dec 2025 — The report draws on two virtual meetings held in July and October 202...
-
Source: babl.ai
Link: https://babl.ai/international-ai-safety-report-warns-of-emerging-frontier-risks-as-capabilities-accelerate/Source snippet
and systemic risks. Documented misuse includes AI-assisted...Read more...
Additional References
-
Source: ddg.fr
Link: https://www.ddg.fr/actualite/frontier-artificial-intelligence-what-the-uk-ai-security-institute-2025-report-reveals-about-risk-safety-and-legal-responsibilitySource snippet
Frontier AI: Risks, Safety and Legal Accountability15 Jan 2026 — The AISI 2025 report warns of rapid AI progress, persistent flaws and ur...
-
Source: linkedin.com
Title: part 5 international ai safety report 2026 governance john shay fporc
Link: https://www.linkedin.com/pulse/part-5-international-ai-safety-report-2026-governance-john-shay-fporcSource snippet
PART 5 OF 5 — International AI Safety Report 2026These documents outline: Internal risk thresholds; Evaluation triggers; Commitments to p...
-
Source: rand.org
Link: https://www.rand.org/content/dam/rand/pubs/conf_proceedings/CFA3400/CFA3429-1/RAND_CFA3429-1.pdfSource snippet
ions, outline the complexities of eval- uating AI for dangerous capabilities, and...Read more...
-
Source: data.x.ai
Title: 2025 12 31 xai frontier artificial intelligence framework
Link: https://data.x.ai/2025-12-31-xai-frontier-artificial-intelligence-framework.pdfSource snippet
Frontier Artificial Intelligence FrameworkDec 30, 2025 — Our safety evaluation and mitigation strategy focuses on individual model behavi...
-
Source: forum.effectivealtruism.org
Title: the world s first frontier ai regulation is surprisingly
Link: https://forum.effectivealtruism.org/posts/Z4DYcBDd36mwr5Xpq/the-world-s-first-frontier-ai-regulation-is-surprisinglySource snippet
world's first frontier AI regulation is surprisingly thoughtful22 Sept 2025 — Up until mid 2023, leading AGI companies had made many info...
-
Source: aigi.ox.ac.uk
Title: Open Problems in Frontier AI Risk Management Final
Link: https://aigi.ox.ac.uk/wp-content/uploads/2026/02/Open-Problems-in-Frontier-AI-Risk-Management-Final.pdfSource snippet
Problems in Frontier AI Risk Management22 Feb 2026 — Frontier AI poses significant safety risks (Bengio et al., 2026). It broadens access...
-
Source: lordslibrary.parliament.uk
Title: potential future risks from autonomous ai systems
Link: https://lordslibrary.parliament.uk/potential-future-risks-from-autonomous-ai-systems/Source snippet
future risks from autonomous AI systems5 Jan 2026 — The 2025 'International AI safety report', commissioned by the 30 countries that atte...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/governing-frontier-ai-lessons-from-2025-international-bhwwcSource snippet
Governing Frontier AI: Lessons from the 2025 International...The 2025 International AI Safety Report, or IASR 2025, steps in as a key guide...
-
Source: assets.amazon.science
Link: https://assets.amazon.science/a7/7c/8bdade5c4eda9168f3dee6434fff/pc-amazon-frontier-model-safety-framework-2-7-final-2-9.pdfSource snippet
amazon.scienceAmazon's Frontier Model Safety Framework9 Feb 2025 — When evaluations demonstrate that an Amazon frontier model has crossed...
-
Source: youtube.com
Title: Evan Hubinger (Anthropic)—Deception, Sleeper Agents, Responsible Scaling
Link: https://www.youtube.com/watch?v=S7o2Rb37dV8Source snippet
Setting a High Standard for Frontier Model Security – Beck, Ludwig, and Xavi...
Amazon book picks
Further Reading
Books and field guides related to Frontier AI Risk Thresholds. Use these as the next step if you want deeper reading beyond the article.

The Oxford Handbook of AI Governance
As the capabilities of Artificial Intelligence (AI) have increased over recent years, so have the challenges of how to govern its usage....

Architectures of Global AI Governance
The impacts of artificial intelligence (AI) are often framed as an uncontrollable wave of technological change. But AI's trajectory is no...

Regulatory Challenges of AI Governance in the Era of ChatGPT
The increasing integration of artificial intelligence (AI), and particularly of large language models (LLMs) like ChatGPT, into human int...

Foundational Principles of AI Governance and Policy
This edited volume provides a structured analysis of AI governance principles, challenges, and implementation strategies. Drawing on inte...
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.

Example eBay listing
artificial intelligence Framed Wall Art Poster Canvas Print Picture
USD 40.12 | GB

Example eBay listing
artificial intelligence Framed Wall Art Poster Canvas Print Picture
USD 40.12 | GB

Example eBay listing
Artificial intelligence Framed Wall Art Poster Canvas Print Picture
USD 40.12 | GB

Example eBay listing
A.I. Artificial Intelligence Movie Poster Print, Wall Art - Unframed
USD 17.95 | Free shipping | US
Topic Tree